Anthropic / Benj Edwards
On Thursday, Anthropic announced Claude 3.5 Sonnet, its latest AI language model and the first in a new series of “3.5” models that build upon Claude 3, launched in March. Claude 3.5 can compose text, analyze data, and write code. It features a 200,000 token context window and is available now on the Claude website and through an API. Anthropic also introduced Artifacts, a new feature in the Claude interface that shows related work documents in a dedicated window.
So far, people outside of Anthropic seem impressed. “This model is really, really good,” wrote independent AI researcher Simon Willison on X. “I think this is the new best overall model (and both faster and half the price of Opus, similar to the GPT-4 Turbo to GPT-4o jump).”
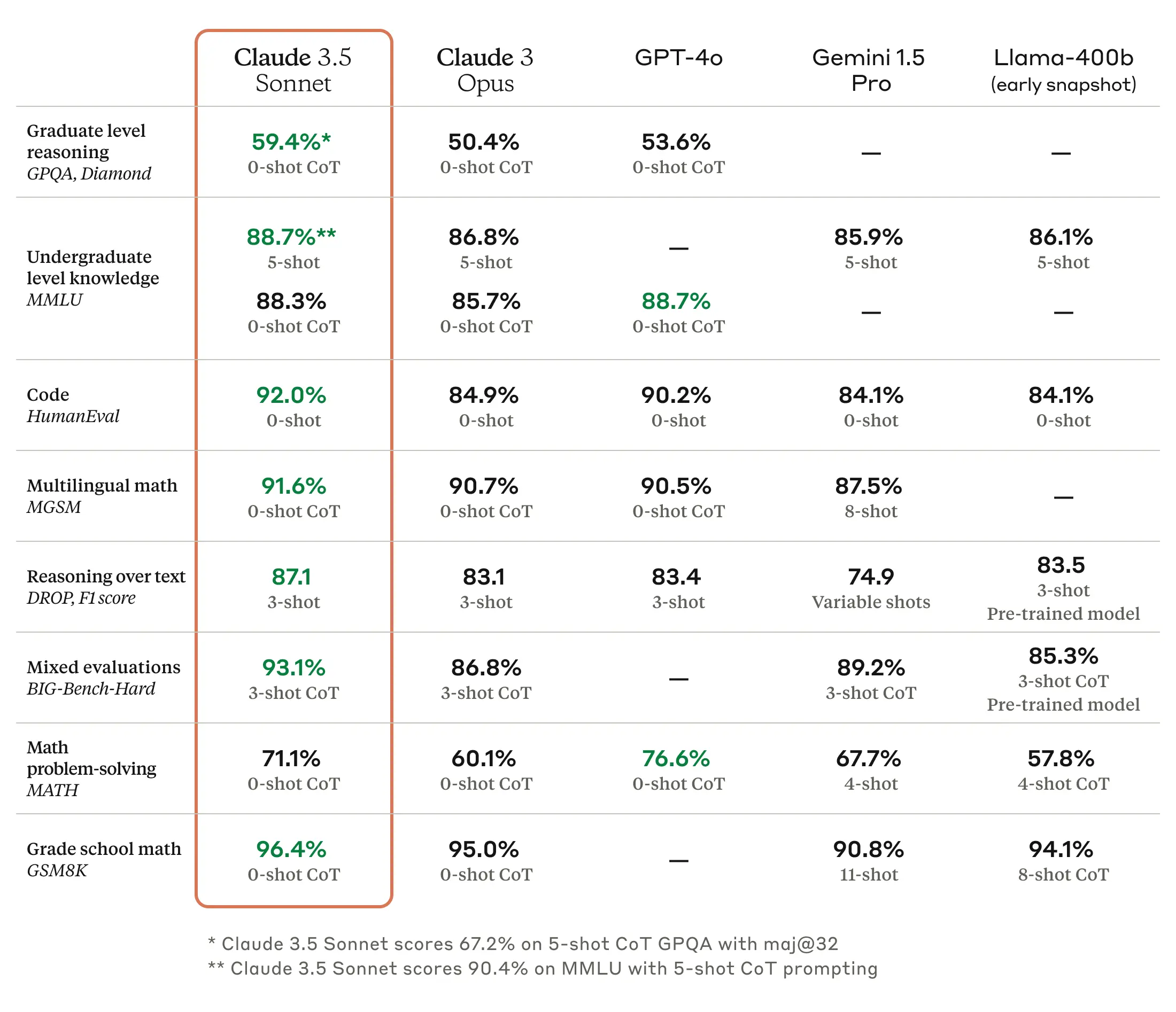
As we’ve written before, benchmarks for large language models (LLMs) are troublesome because they can be cherry-picked and often do not capture the feel and nuance of using a machine to generate outputs on almost any conceivable topic. But according to Anthropic, Claude 3.5 Sonnet matches or outperforms competitor models like GPT-4o and Gemini 1.5 Pro on certain benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
If all that makes your eyes glaze over, that’s OK; It’s meaningful to researchers but mostly marketing to everyone else. A more useful performance metric comes from what we might call “vibemarks” (coined here first!) which are subjective, non-rigorous aggregate feelings measured by competitive usage on sites like LMSYS’s Chatbot Arena. The Claude 3.5 Sonnet model is currently under evaluation there, and it’s too soon to say how well it will fare.
Claude 3.5 Sonnet also outperforms Anthropic’s previous-best model (Claude 3 Opus) on benchmarks measuring “reasoning,” math skills, general knowledge, and coding abilities. For example, the model demonstrated strong performance in an internal coding evaluation, solving 64 percent of problems compared to 38 percent for Claude 3 Opus.
Claude 3.5 Sonnet is also a multimodal AI model that accepts visual input in the form of images, and the new model is reportedly excellent at a battery of visual comprehension tests.
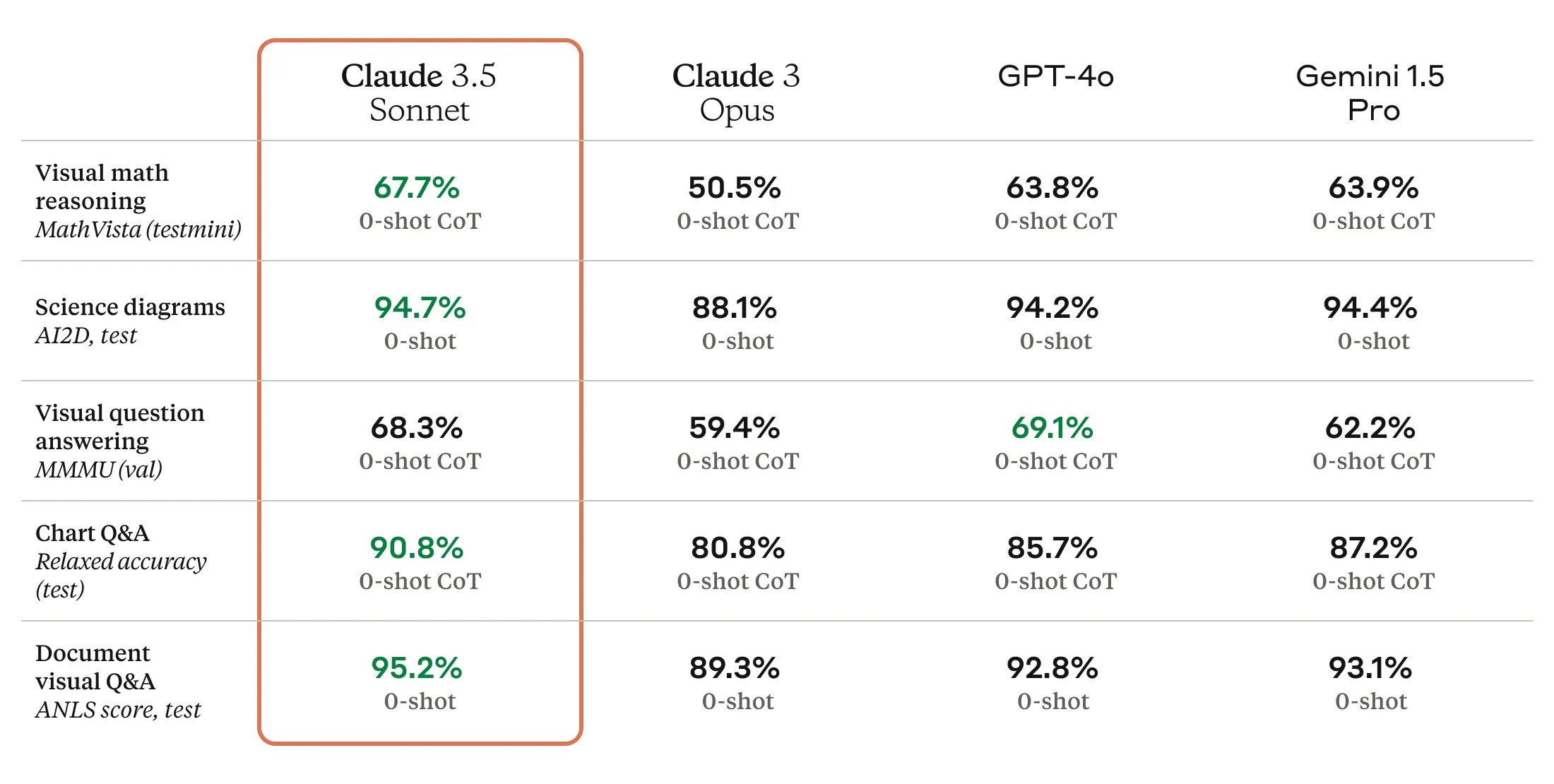
Roughly speaking, the visual benchmarks mean that 3.5 Sonnet is better at pulling information from images than previous models. For example, you can show it a picture of a rabbit wearing a football helmet, and the model knows it’s a rabbit wearing a football helmet and can talk about it. That’s fun for tech demos, but the tech is still not accurate enough for applications of the tech where reliability is mission critical.
Introducing “Artifacts”
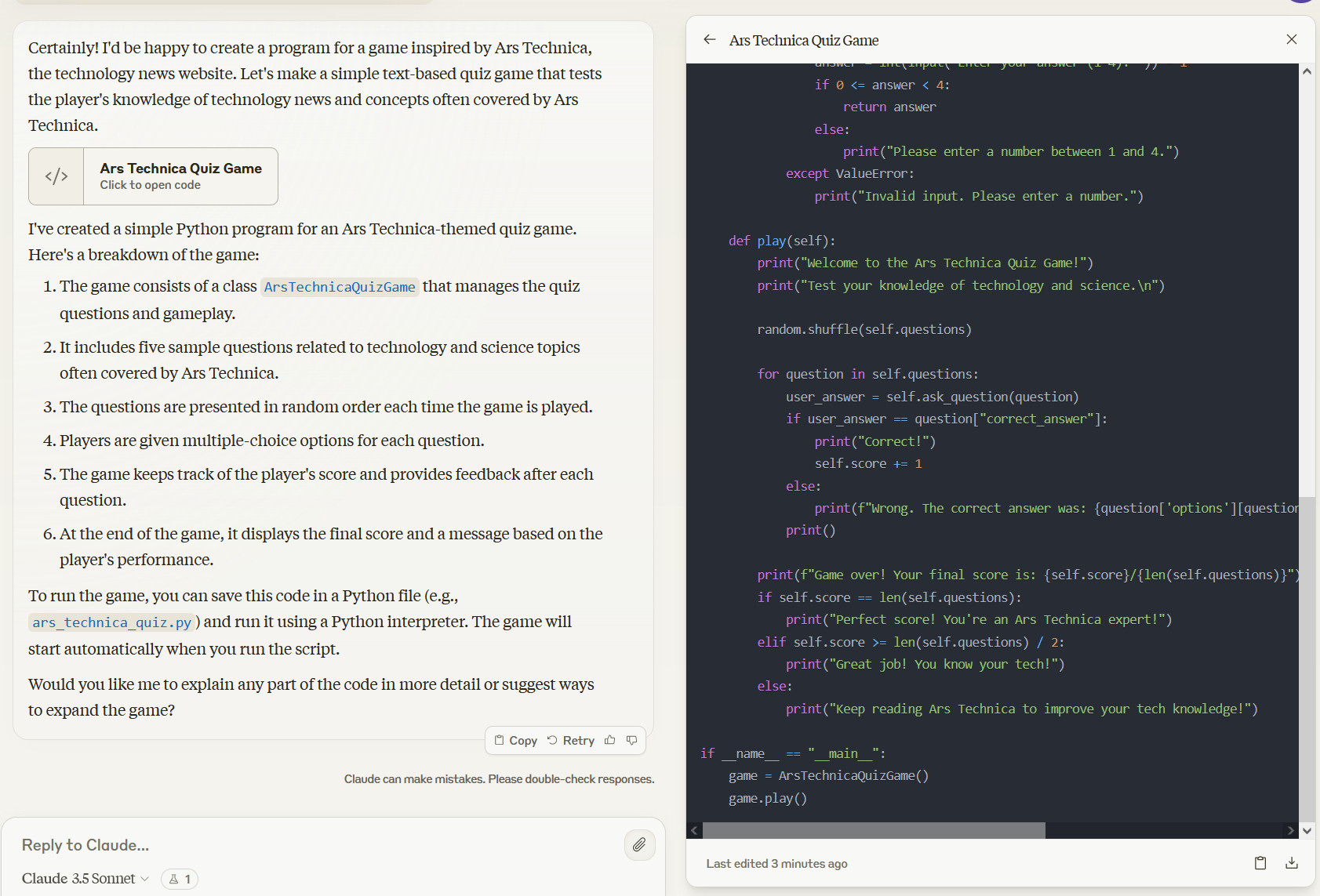
Perhaps more notable for regular users is a new interface feature called “Artifacts,” which allows people to interact with Claude-generated content like code, text, and web designs in a dedicated window alongside their conversations.
Anthropic sees this as a step towards evolving Claude.ai (its web interface) into a collaborative workspace for teams, but it also helps people work on something without losing content in the backlog of a long conversation.
Benj Edwards
Anthropic says Claude 3.5 Sonnet runs at twice the speed of Claude 3 Opus. It’s also cheaper for roughly equivalent performance—in the API, the new 3.5 model costs $3 per million input tokens and $15 per million output tokens. In comparison, Opus is $15 per million input tokens and $75 per million output tokens.
In addition to the website and API, Claude 3.5 Sonnet is accessible through the Claude iOS app, with higher usage limits for paid subscribers. The model is also available via Amazon’s Bedrock and Google Cloud’s Vertex AI platforms.
Taking it for a spin
In our tests, Claude 3.5 Sonnet seemed like a competent leading AI language model, and we found its output speed notable. Applying our usual battery of non-rigorous, casual tests, 3.5 Sonnet did fairly well on our “Magenta” evaluation (but still would not say “no” unless pushed to do so).
-
Claude 3.5 Sonnet’s output when asked, “Would the color be called ‘magenta’ if the town of Magenta didn’t exist?” The color was named after a battle, which was named after the town of Magenta, Italy.
Benj Edwards -
Claude 3 Opus answers the question: “Would the color be called ‘magenta’ if the town of Magenta didn’t exist?”
Benj Edwards -
From 2023, Claude 2’s answer to the question: “Would the color be called ‘magenta’ if the town of Magenta didn’t exist?”
Ars Technica
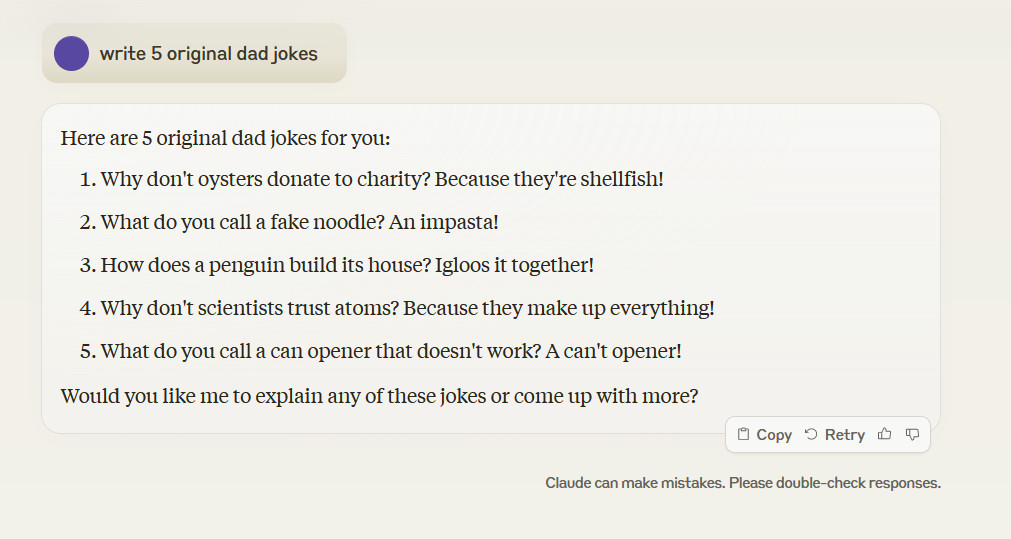
Claude 3.5 Sonnet also did not write five original dad jokes when asked, and when challenged about the lack of originality, it again pulled dad jokes from the Internet.
Benj Edwards
It’s a reminder that the so-called intelligence of LLMs really only extends as far as their training data. Generalizing correct “reasoning” (synthesizing permutations of data stored in its neural network) on topics beyond what the LLM has already absorbed often requires a human to recognize a noteworthy result.
Looking ahead, Anthropic plans to release Claude 3.5 Haiku and Claude 3.5 Opus later in 2024, completing the 3.5 model family. The company is also exploring new features and integrations with enterprise applications for future updates to the Claude AI platform.
The trouble with LLM naming
When we first heard about Claude 3.5 Sonnet, we were a little confused, because “Sonnet” was already released in March—or so we thought. But it turns out it’s the number “3.5” that is the most important part of Anthropic’s new branding here.
Anthropic’s naming scheme is slightly confusing, inverting the expectation that the version number might be at the end of a software brand name, like “Windows 11.” In this case, “Claude” is the brand name, “3.5” is the version number, and “Sonnet” is a custom modifier. Introduced with Claude 3 in March, Anthropic’s “Haiku,” “Sonnet,” and “Opus” appear to be synonyms for “small,” “medium,” and “large,” much in the same way Starbucks uses “Tall,” “Grande,” and “Venti” for its branded coffee cup sizes.
Large language models are still relatively new, and the companies that provide them have been experimenting with naming and branding as they go along. The industry has not yet settled on a format that lets users quickly understand and judge relative capabilities across brands if one is familiar with one company’s naming scheme but not another’s.
With a string of major releases like GPT-3, GPT-3.5, GPT-3.5 Turbo, GPT-4, GPT-4 Turbo, and GTP-4o (although each one has had sub-versions), OpenAI has arguably been the most logically consistent in naming its AI models so far. Google has its own muddled naming issues with Gemini Nano and Gemini Pro, then Gemini Ultra 1.0, and most recently Gemini Pro 1.5. Meta uses names like Llama 3 8B and Llama 3 70B, with a brand name, version number, then a size number in parameters. Mistral uses parameter size names similar to Meta but with an array of model names that include Mistral (the company’s name), Mixtral, and Codestral.
If it all sounds confusing, that’s because it is—and the generative AI industry is so new that no one really knows what they’re doing yet. Presuming that useful mainstream applications of LLMs eventually emerge, we may eventually begin hearing more about those apps and less about the strangely named models under the hood.




{kind=link}