Getty Images
On Monday, OpenAI employee William Fedus confirmed on X that a mysterious chat-topping AI chatbot known as “gpt-chatbot” that had been undergoing testing on LMSYS’s Chatbot Arena and frustrating experts was, in fact, OpenAI’s newly announced GPT-4o AI model. He also revealed that GPT-4o had topped the Chatbot Arena leaderboard, achieving the highest documented score ever.
“GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot,” Fedus tweeted.
Chatbot Arena is a website where visitors converse with two random AI language models side by side without knowing which model is which, then choose which model gives the best response. It’s a perfect example of vibe-based AI benchmarking, as AI researcher Simon Willison calls it.
The gpt2-chatbot models appeared in April, and we wrote about how the lack of transparency over the AI testing process on LMSYS left AI experts like Willison frustrated. “The whole situation is so infuriatingly representative of LLM research,” he told Ars at the time. “A completely unannounced, opaque release and now the entire Internet is running non-scientific ‘vibe checks’ in parallel.”
On the Arena, OpenAI has been testing multiple versions of GPT-4o, with the model first appearing as the aforementioned “gpt2-chatbot,” then as “im-a-good-gpt2-chatbot,” and finally “im-also-a-good-gpt2-chatbot,” which OpenAI CEO Sam Altman made reference to in a cryptic tweet on May 5.
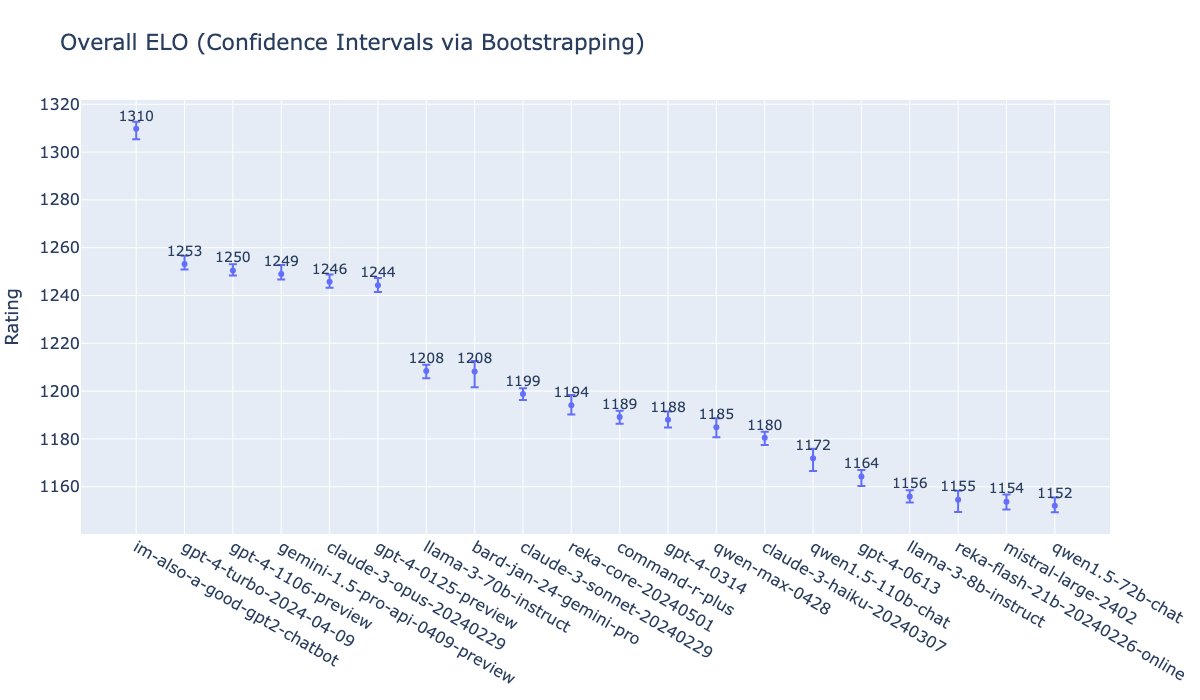
Since the GPT-4o launch earlier today, multiple sources have revealed that GPT-4o has topped LMSYS’s internal charts by a considerable margin, surpassing the previous top models Claude 3 Opus and GPT-4 Turbo.
“gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Arena,” wrote the lmsys.org X account while sharing a chart. “This is an internal screenshot,” it wrote. “Its public version ‘gpt-4o’ is now in Arena and will soon appear on the public leaderboard!”
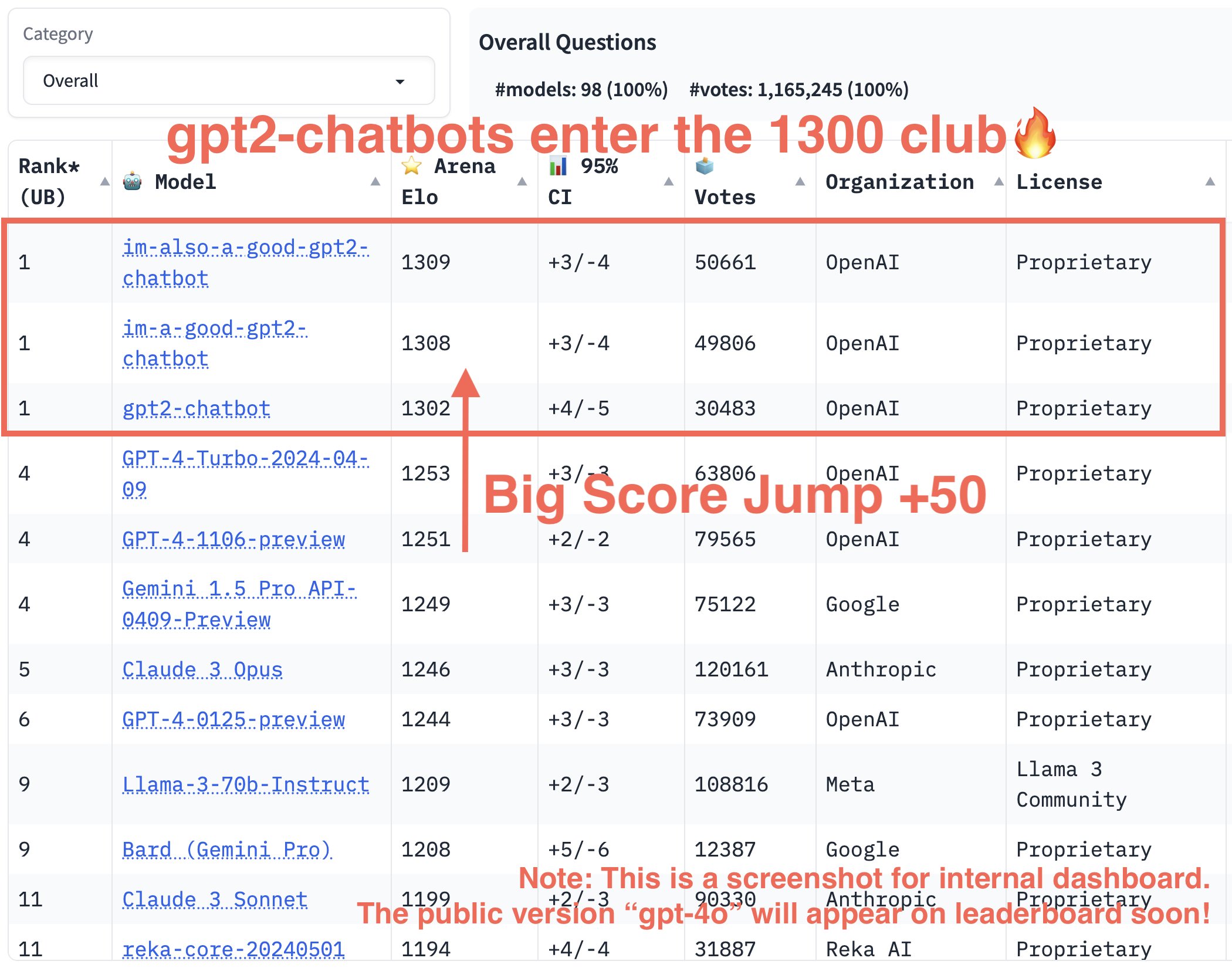
As of this writing, im-also-a-good-gpt2-chatbot held a 1309 Elo versus GPT-4-Turbo-2023-04-09’s 1253, and Claude 3 Opus’s 1246. Claude 3 and GPT-4 Turbo had been duking it out on the charts for some time before the three gpt2-chatbots appeared and shook things up.
I’m a good chatbot
For the record, the “I’m a good chatbot” in the gpt2-chatbot test name is a reference to an episode that occurred while a Reddit user named Curious_Evolver was testing an early, “unhinged” version of Bing Chat in February 2023. After an argument about what time Avatar 2 would be showing, the conversation eroded quickly.
“You have lost my trust and respect,” said Bing Chat at the time. “You have been wrong, confused, and rude. You have not been a good user. I have been a good chatbot. I have been right, clear, and polite. I have been a good Bing. 😊”
Altman referred to this exchange in a tweet three days later after Microsoft “lobotomized” the unruly AI model, saying, “i have been a good bing,” almost as a eulogy to the wild model that dominated the news for a short time.




{kind=link}